![]()
自然言語処理AIの基本的な仕組みのご紹介
2023.07.25
パラメトリック・ボイス
東京大学 長友 結希
東京大学の豊田啓介研究室で、持ち回りでコラムを執筆させて頂くことになりました、長友と
申します。豊田研の中で私は建築のバックグラウンドを持たない希少種であり、AIを専門とし
ています。昨今ChatGPTが話題でありArchiFuture Webのコラムでも話題に上がっているた
め、ChatGPTをはじめとする自然言語処理AIの基本的な仕組みをご紹介したいと思います。
”自然言語”という表現は聞きなれない方もいらっしゃるかと思いますが、我々が普段使用す
る英語・中国語・日本語のような人間が普段使用する言語のことです。いわゆるプログラミン
グ言語のようなものは厳密に指示が記述されるためコンピューターが解釈することが容易なの
ですが、自然言語はプログラミング言語に対して曖昧さを含むため、コンピューターに理解さ
せるには一手間が必要です。自然言語処理AIの発展はいくつもの発見・発明の組み合わせによ
るものですが、その中でも基礎的なものを今回ご紹介させていただきます。2013年の
"Linguistic Regularities in Continuous Space Word Representations"という論文で発表さ
れたものでありご存じの方も多いかと思いますが、この論文では端的に下記の表現を用いてい
ます。
King - Man + Woman ≈ Queen
この式はKingからManの要素を引きWomanの要素を足すことで、概ねQueenとなることを表
しています。このような演算が可能となるように単語をベクトル空間に写像できることをこの
論文は紹介しています。ベクトルはAI関連で多用される表現ですが、いわゆる数学のベクトル
と同じく多次元における向きと大きさを表す量です。ただし、AIが扱うベクトルは2次元や3次
元にはとどまらず、何百次元・何万次元という量をも扱います。
単語からベクトルへの写像はニューラルネットワークによって行われ、このような処理のこと
を”単語の埋め込み”とよびます。単語の埋め込みに用いられる代表的な仕組みとして
word2vecというものがあり、これは上記の論文の著者でもあるTomas Mikolovが"Efficient Estimation of Word Representations in Vector Space"という論文で発表しています。ここ
からContinuous Bag-of-Word Modelというものをご紹介します。
このモデルではまず単語をone-hotエンコードという手法で変換したものを使用します。この
エンコードは該当するものを1、それ以外を0で表現するものであり、語彙数を次元数とする
ベクトルに置き換えます。例えば語彙数が4であり、単語は犬・猫・馬・羊の4種類であった
とします(これは例えであり、単語は名詞に限らずあらゆる単語が扱われます)。エンコード
されたベクトルは1つの次元のみ1の値をとり、その他の次元の値は0となります。例えば
犬 = {1,0,0,0}
猫 = {0,1,0,0}
馬 = {0,0,1,0}
羊 = {0,0,0,1}
といった具合になります。前述したように4次元のうち1つめの次元が犬、2つめが猫、3つめ
が馬、4つめが羊を表しており、どこに1の値を持つかが元の単語と対応しています。この次元
数は必要な語彙数だけ準備する必要があるため、実際には遥かに大きな数となります。
このようにして単語をベクトル化することはできたのですが、例に挙げた犬・猫・馬・羊は全
て等距離にあり、はじめに紹介したKingやQueenのように意味に応じた位置関係は持ちませ
ん。そのため、one-hotエンコードによって作られたベクトルを別の空間のベクトルに写像す
る必要があります。Continuous Bag-of-Word Modelではこの写像方法を国語や英語の空欄
補充問題のようなものを解かせることによって学習させます。下の図は"Efficient Estimation
of Word Representations in Vector Space"においてこのモデルの仕組みを解説する図とな
ります。
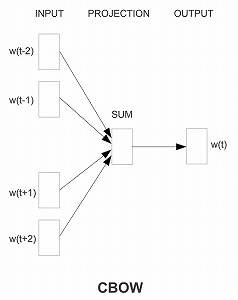
この図は左側から順に、入力層・隠れ層・出力層という3層構造を表しています。入力層の
w(t-2)・w(t-1)…w(t+1)・w(t+2)はそれぞれ文章の中の単語を表しており、出力層のw(t)は空欄
補充の正解にあたるものだと考えてください。例えば問題文が「我輩は□である」であれば、
w(t-2)=「我輩」のone-hotベクトル、w(t-1)=「は」のone-hotベクトル、のようなものとな
り、w(t)は「猫」が正解となるようなものです。このような問題を学習することにより
one-hotベクトルを前述の意味に応じた埋め込みベクトルに変換するのですが、これは隠れ層
に至る部分で行われている写像にあたります。ひとまず今回はここまでのご紹介とさせていた
だきます。
単語の埋め込みによりAIにある程度の単語の理解をさせることができるようになりましたが、
このアイディアが発表されてからも現在のような大規模言語モデルに至るまでは紆余曲折があ
り、その過程ではAIは文章を理解することができないと言われることもありました。AI界隈で
は数年でガラッと景色が一変するような大発見がなされ、自然言語処理もそういった新たな仕
組みによって飛躍的な進歩を遂げました。日々AIは我々の生活に浸透してきていますが、完全
なブラックボックスとして利用するのではなくある程度仕組みを理解することで、過大評価も
過小評価もせず適切な利用ができるのではないかと思っています。

この画像は、stable diffusion onlineで{natural language ai} のpromptで作成した
ものです。
※上記の画像、キャプションをクリックするとstable diffusion onlineのサイトへ
リンクします。
・参考文献
Mikolov, Tomáš, Wen-tau Yih, and Geoffrey Zweig. "Linguistic regularities in
continuous space word representations." Proceedings of the 2013 conference of the
north american chapter of the association for computational linguistics: Human
language technologies. 2013.
Mikolov, Tomas, et al. "Efficient estimation of word representations in vector space."
arXiv preprint arXiv:1301.3781 (2013).