
![]()
生成AIとインスタンスセグメンテーション
による未来景観表現
2024.01.09
パラメトリック・ボイス 大阪大学 福田 知弘
未来の景観表現: AIの可能性
都市では、既存建物を取り壊して新たな建物を建設するという行為が繰り返されます。未来の
景観を検討する際には、施主、設計者、住民など多様なステークホルダーが理解できるように、
視覚的に表現されることが必要です。これまでの表現手段は労力やスキルの問題が内在してい
るため、深層学習を用いた画像生成技術が新しい表現法として期待されています。画像生成AI
を使えば、非専門家も建物の取り壊し後や再建築後の姿を視覚的に表現できます。一方、思い
通りの未来図を描いてくれない悩みがあります。
これまでの研究*1 では、セマンティックセグメンテーション1) と敵対的生成ネットワーク(GAN)
という画像生成技術を使用して取り壊し後の景観をDR(隠消現実)として生成する方法が提案
されました。しかし、特定の建物を選択的に取り除くことが難しい上、再建築後の景観を生成で
きないという課題があります。
インスタンスセグメンテーションと拡散モデルの融合
そこで筆者らは、インスタンスセグメンテーション2) と拡散モデル3) を組み合わせて、既存建
物の取り壊し後と再建築後の景観画像を生成できる方法を開発しました。再建築後の景観画像
は、テキスト入力に基づいて生成されます。以下の3つの主要なプロセスから構成されていま
す。
1.建物の個別検出:インスタンスセグメンテーションを使用して、対象となる建物が含まれ
る景観画像から建物を個別に検出します。各建物には一意のIDが割り当てられます。
2.マスク画像自動生成:ユーザーが選択した建物とその周囲のエリアを単色で塗りつぶした
マスク画像を自動作成します。
3.未来の景観画像生成:マスクされた領域に対して、選択した建物が取り除かれた画像が生
成されます。または、ユーザーがテキスト入力した内容に基づいて、新しい建物が生成され
ます。画像生成には、拡散モデルが使用されます。
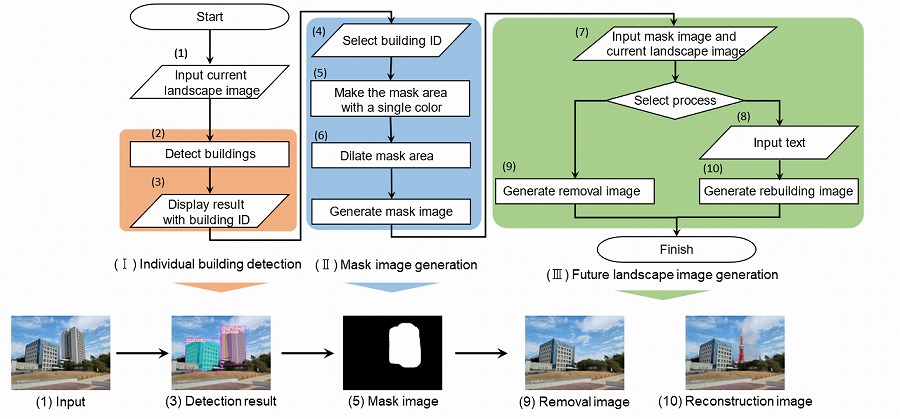
図1 提案フロー:(オレンジ)建物の個別検出、(ブルー)マスク画像生成、(グリーン)
未来の景観画像生成
プロトタイプシステムの開発と検証
提案方法の有効性を検証するために、プロトタイプシステムを開発しました。システムでは、
まず、インスタンスセグメンテーションの学習用データセットには建物のデータセットが存在
していないため、建物を含む画像のデータセットを作成しました。また、拡散モデルには
Stable Diffusionを使用しました。
検証実験では、建物の個別検出の正確さ、建物の除去の正確さ、およびテキスト入力による再
建築画像生成の正確さの3つの視点から評価しました。これには、mAP(mean Average
Precision:平均精度の平均)、色差式(CIE DE2000)などの評価指標を使用して、プロトタ
イプシステムの性能を評価しました。

図2 結果:(左)入力画像、(左中)建物の個別検出、(右中)建物解体撤去後の出力、
(右)再建築後の出力(赤枠:生成領域)
成果と課題
新しい提案法は、個別建物を検出した上で、建物解体撤去後、および、再建築後の未来景観を
自動生成することが可能です。建物検出では、大きな建物に対しては高い精度が得られた一方
で、建物に内部の境界や類似したファサードの部分が存在する場合には課題が残りました。解
体撤去後の画像は90%以上の精度で生成可能であり、再建築後の画像も高い精度が得られまし
た。ただし、テキスト入力による生成の正確さは入力内容により差異があり、より複雑なテキ
ストの入力は今後の課題です。
この研究成果は、オーストリア・グラーツ工科大学で開催されたEducation and Research in
Computer Aided Architectural Design in Europe(eCAADe)の2023年国際会議で口頭発表
しました*2。全文査読を通過した論文は、論文データベースScopusやCuminCADにインデック
スされています。

図3 オーストリア・グラーツで開催されたeCAADe 2023で、筆頭著者である博士前期課程
1年・麦田氏が口頭発表しました。

図4 学会発表前の期間を利用して、グラーツの現地調査を行い、市内の建物を対象として、
提案システムを使って実験しました。(左)入力画像、(中)インスタンスセグメン
テーション、(右)出力結果。
口頭発表では、これらの画像でデモンストレーションしました。オーディエンスからは
質問が相次ぎました。
用語の説明
1) セマンティックセグメンテーション:画像内の異なる領域を物体や要素の種類に基づいて
分割する技術です。具体的には、画像内の各ピクセルがどのクラス(例: 道路、車、樹木)
に属するかを識別します。この方法は、画像理解の向上や自動運転技術など、さまざまな
応用分野で利用されています。
2) インスタンスセグメンテーション:写真や画像内の異なる物体や要素を個別に識別し、そ
れぞれを異なる領域として区別する技術です。例えば、写真に写る異なる人物や動物、ま
たは建物などがそれぞれ別々に区別され、特定されることを指します。この方法は、画像
処理やコンピュータビジョンの分野で広く利用され、物体検知や画像認識の向上に寄与し
ています。
3) 拡散モデル:画像生成AIに採用されている学習モデルの1つであり、データの拡散過程(ノ
イズが付与されて破壊される過程)を学習したモデルのこと。このモデルは、元の画像デー
タにノイズを加えていくForward Processと、ノイズ分布の状態からノイズを除去するこ
とで画像データを作成するReverse Processの2つに分かれています。
参考文献
*1 Kikuchi, T., Fukuda, T., Yabuki, N. (2022). Diminished reality using semantic segmentation and generative adversarial network for landscape assessment:
Evaluation of image inpainting according to colour vision, Journal of Computational
Design and Engineering, Volume 9, Issue 5, 1633–1649,
*2 Mugita, Y., Fukuda, T., Yabuki, N. (2023). Future Landscape Visualization by
Generating Images Using a Diffusion Model and Instance Segmentation, Proceedings
of the 41st Conference on Education and Research in Computer Aided Architectural
Design in Europe (eCAADe 2023), Volume 2, 549–558,
最新の記事

























